Klasterizacija k-means algoritmom u Excel-u

Klasterska analiza je postupak kojim se skup objekata grupira u grupe tj. u disjunktne podskupove. Pritom objekti iz iste grupe (klastera) moraju biti međusobno što više slični, a objekti iz različitih grupa moraju biti što manje slični. Klasterska analiza, osim brojnih primjena u biologiji, medicini, informacijskim znanostima, analizi društvenih mreža, urbanizmu itd., primjenjuje se i u poslovanju. Primjerice, može se koristiti za identifikaciju grupa korisnika obaveznog automobilskog osiguranja s visokim prosječnim odštetnim zahtjevima. U marketinškim istraživanjima je klasterska analiza uobičajen alat, a najčešće se primjenjuje za:
- particioniranje ciljane populacije u tržišne segmente, a radi boljeg uvida i razumijevanja različitih grupa kupaca ili potencijalnih kupaca
- grupiranje artikala u smislene grupe
- pozicioniranje proizvoda
- razvoj novih proizvoda
- razvoj ciljanih marketinških programa ili promocijskih kampanja, itd.
K-means algoritam za klasterizaciju je često korišten nehijerarhijski algoritam kojim se svi objekti smještaju u točno jedan od k disjunktnih podskupova. Pritom je k, tj. broj klastera, potrebno unaprijed odrediti. Naziv se ponekad prevodi kao algoritam k-sredina.
Opis algoritma:
- Odredi se početnih k centara zamišljenih klastera slučajnim odabirom njihovih koordinata.
- Na temelju određenih centara formira se k klastera na način da se svaki objekt uvrsti u klaster čiji mu je centar najbliži. Na ovaj način se udaljenost koristi kao mjera sličnosti među objektima. Može se koristiti klasična tj. Euklidska udaljenost, a ovisno o vrsti i distribuciji varijabli i neka druga udaljenost (Minkowski, Manhattan, ...)
- Svakom formiranom klasteru određuje se novi centar. Novi centar se određuje kao težište formiranog klastera. Njegove koordinate se dobivaju kao aritmetička sredina odgovarajućih koordinata članova klastera.
- Ponavlja se korak br. 2, ali s novim središtima. To dovodi do premještanja nekih objekata iz jednog klastera u drugi. Promjena sastava objekata u svakom klasteru dovodi do promjene težišta, pa se ponavlja i korak br. 3. Ponavljanjem koraka br. 2 i br. 3, centri klastera se pomiču prema svojoj konačnoj poziciji.
Drugi i treći korak ponavljaju se uzastopno sve dok ima promjena u rasporedu objekata u klastere. Postupak se može prekinuti i ako se postavljena mjera kvalitete particioniranja (zbroj kvadrata udaljenosti svih objekata od centra svog klastera) prestane značajno mijenjati.
Ovaj algoritam je, zbog svoje upotrebljivosti, sastavni dio mnogih data mining softverskih paketa. MS Excel nema ugrađeni automatizirani dodatak za ovu vrstu analize, ali ju je moguće provesti klasičnim tabličnim izračunima. U nastavku slijedi primjer klasterizacije k-means algoritmom koja je izvedena u Excelu. Radi zadržavanja mogućnosti vizualizacije, za dani skup promatrane su samo dvije varijable.
Primjer:
Menadžer jedne specijalizirane trgovine odlučio je, radi ciljanog pristupa, podijeliti svoje poznate kupce u grupe na temelju podataka o broju njihovih dodlazaka u trgovinu, te na temelju prosječne potrošnje po dolasku. Promatranih kupaca je 30.
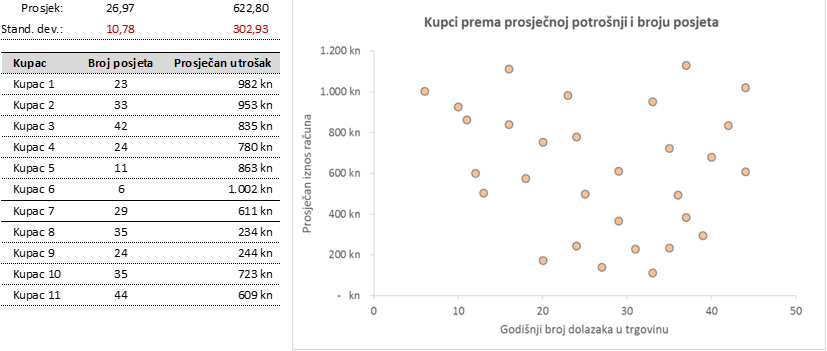
Slika 1: Početni retci tablice s podacima i dijagram rasipanja – kupci prema broju dolazaka i prosječnoj potrošnji
Budući da se promatrane varijable značajno razlikuju u vrijednostima, uputno je prije provedbe algoritma vrijednosti normalizirati. Time se izbjegava davanje veće težine varijabli s većim vrijednostima. Jedan od načina da se podaci naprave usporedivima je njihovo preslikavanje u standardizirane vrijednosti, tj. u tzv. z-vrijednosti. U tu svrhu bilo je potrebno za obje varijable izračunati aritmetičku sredinu i standardnu devijaciju. Korištene su Excel funkcije AVERAGE i STDEV.P. Za svakog kupca, standardizirane vrijednosti obiju varijabli računaju se po formuli:
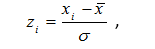
gdje su Xi vrijednost promatrane varijable za i-tog kupca, a ![]() aritmetička sredina i standardna devijacija te varijable.
aritmetička sredina i standardna devijacija te varijable.
Tako, primjerice, standardizirana vrijednost varijable Prosječan utrošak za Kupca 1 iznosi 1,19. Naime, s vrijednošću 982 kn prosječne potrošnje po dolasku, on od prosjeka čija je vrijednost 622,80 kn, odstupa za 1,19 standardnih devijacija tj. prosječnih odstupanja.
Nakon standardizacije, slijedi provedba opisanog algoritma. Početni centri određeni su proizvoljno, na temelju izrađenog dijagrama rasipanja. Svi izračuni rađeni su sa standardiziranim vrijednostima koje su se, pak, za potrebe jasnog grafičkog prikaza, opet preračunavale u originalne vrijednosti.
Donja slika pokazuje stanje nakon unosa koordinata početnih triju centara (15,400), (30,500) i (45,600). One su unesene u gornju tablicu u trećem stupcu.

Slika 2: Izračun udaljenosti od središta i određivanje novih središta
U središnjoj tablici računaju se udaljenosti svakog objekta (točke) od sva tri centra klastera. U njenom zadnjem stupcu, na temelju prepoznavanja najmanje udaljenosti (označena zelenom pozadinom), određuje se kojem klasteru (1, 2 ili 3) taj kupac pripada. Korištena je IF funkcija.

Slika 3: Položaj proizvoljno određenih središta na dijagramu rasipanja
Kada je poznata prva raspodjela kupaca u klastere, određuju se novi centri klastera i to kao težište svake grupe elemenata tj kupaca. To se radi u donjoj desnoj maloj tablici. Koristi se funkcija AVERAGEIF, jer se koordinate novih središta dobivaju kao aritmetička sredina odgovarajućih koordinata samo onih kupaca koji pripadaju tom klasteru.
Sada se koordinate novih središta metodom COPY/PASTE VALUES prenose iz donje desne tablice u gornju desnu tablicu, na mjesta gdje su koordinate središta klastera.

Slika 4: Drugi i treći korak
To dovodi do ponovnog izračunavanja udaljenosti. Pritom neki kupci prijeđu iz jednog klastera u drugi, tj. dobiju novu oznaku klastera. Zbog toga se izračunavaju i nova središta, pa se po potrebi sve može više puta ponoviti.
U ovom primjeru se podjela u klastere stabilizirala nakon tri koraka.
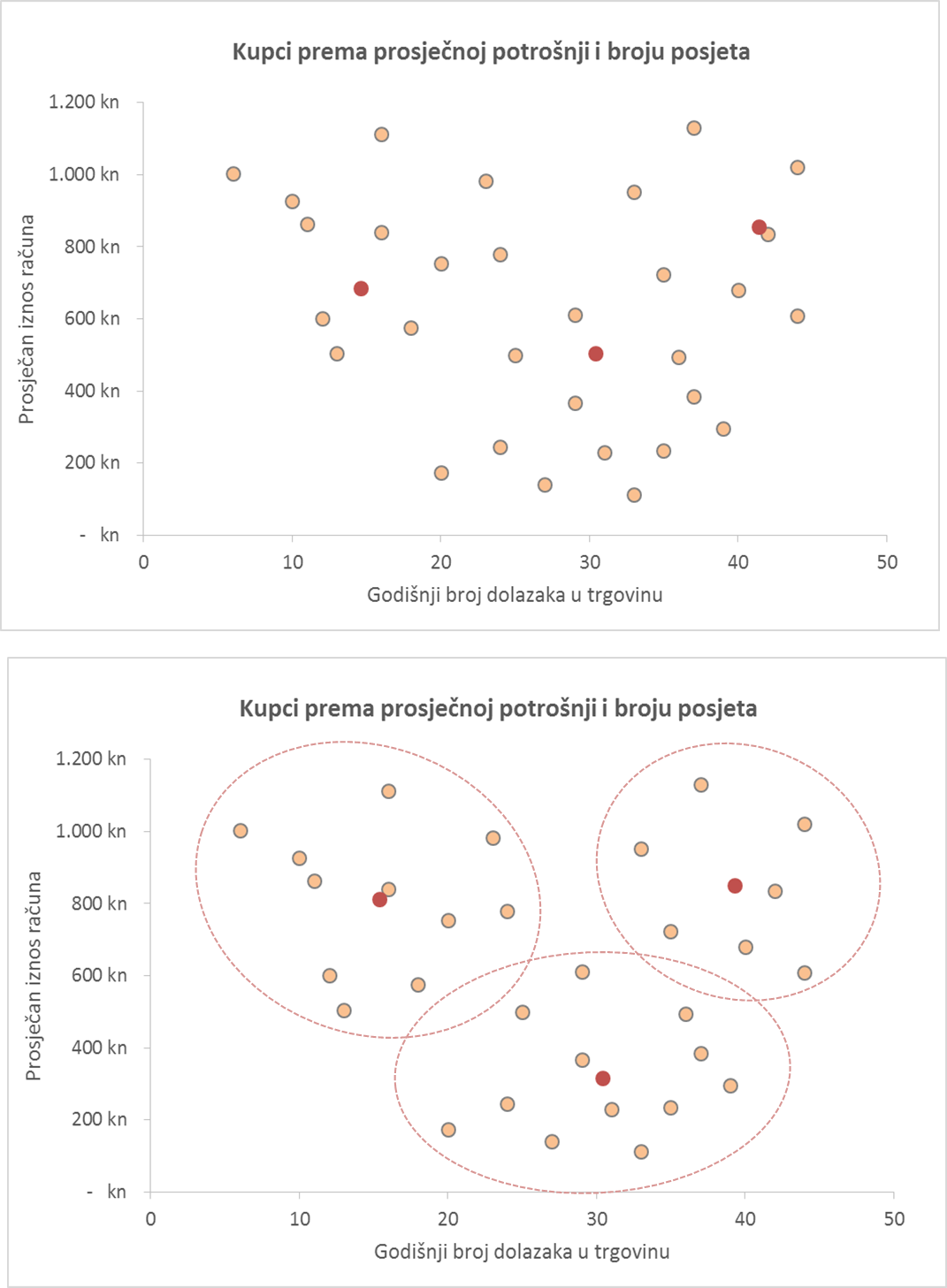
Provedenim postupkom dobivena je podjela u tri klastera. Možemo ih opisno ovako okarakterizirati:
- Klaster 1: Kupci koji dolaze rijeđe, s većom prosječnom potrošnjom
- Klaster 2: Kupci koji dolaze često, relativno niska prosječna potrošnja
- Klaster 3: Kupci koji dolaze često i imaju visoku prosječnu potrošnju-
Na temelju ovih informacija, u nastojanju da poboljša prodaju, menadžer trgovine može odrediti dva različita marketinška pristupa: jedan prema kupcima iz Klastera 1, a drugi prema kupcima iz klastera 2.
Joško Meter, dipl. ing.
Ukoliko želite saznati više prijavite se na specijslističku radionicu "Napredna statistička analiza u Excel-u" koja će se održati 01.09.2020. na adresi Martićeva 73/1, u Zagrebu.
Kolumne